

Вся информация в этом гайде (и часть картинок) взята с разных постов реддита r/StableDiffusion. Рекомендую отслеживать его, если хотите быть в курсе появляющихся новых возможностей программы, найденных лайфхаках для генерации или если у вас появляется вопрос, с которым не помогает гугл.
В этом гайде я в основном описываю шаги, которых будет достаточно пользователю на Windows с видеокартами Nvidia 10XX с 4-6 гигабайтами видеопамяти и выше для запуска на своем компе. Если у вас мощная карта от красных – возможно, вам поможет вот этот гайд.
Все меняется крайне быстро и я не гарантирую, что все шаги будут актуальны через неделю-другую.
1. Введение. Что еще за Stable Diffusion?
Stable Diffusion – программа с открытым исходным кодом от группы Stability.Ai , выпущенная в публичный доступ 22 августа, состоит из 2х больших частей – собственно, обученной нейросети (сейчас доступна версия 1.4, скоро будет доступна 1.5 – в ней обещают более качественные лица/глаза/руки) и обвязки, ее вызывающей.
Результаты ее работы похожи на DALL·E и Midjourney (мне с друзьями показалось, что в среднем Midjourney рисует чуть выразительнее, а Stable Diffusion более четко следует запросу при настройках по умолчанию), главное преимущество с точки зрения пользователя сейчас – нет ограничений на генерируемые изображения (NSWF фильтр есть в оригинале, но легко снимается) и все бесплатно.

“Бесплатно”, запрос от меня – Ryan Gosling smiling, symmetric highly detailed eyes, trending on artstation, portrait, digital art, masterpice, by Vladimir Kush and Scott Naismith
Сообщество растет быстро и уже сейчас есть куча разных вариантов работы с нейросетью:
- Базовый – через консоль. Для тех, кто не боится python и/или чуть-чуть потрогать код. Если готовы – выкачиваете с гитхаба подходящий вам по каким-то соображениям вариант (Исходный вот тут ; вариант для запуска с меньшими затратами видеопамяти и кучей дополнительных опций – тут) и следуете гайду по настройке окружения/запуска (для исходника – вот, для второго варианта – вот). Плюсы – вам проще будет интегрировать новые появляющиеся методы генерации изображений и вы чуть лучше разберетесь в том, как это все работает.
- Через браузер (например, на этом сайте без регистрации и настроек , на этом – с регистрацией и разными настройками ). Плюсы – доступно с любого устройства и ничего не надо устанавливать. Минусы – медленно, меньше возможностей, в любой момент ваш любимый сайт может свернуться из-за наплыва пользователей/желания создателей.
- Через графический интерфейс и установщик. Мне кажется, такой способ должен быть привычнее большинству пользователей Windows, поэтому его и опишу. Минусы – не факт, что в графическом интерфейсе будут все нужные вам настройки. Плюсы – все наглядно и не надо ничего знать про всякие питоны, анаконды, пип-инсталлы, командные консоли…
2. Установка на своём компьютере
Пошагово:
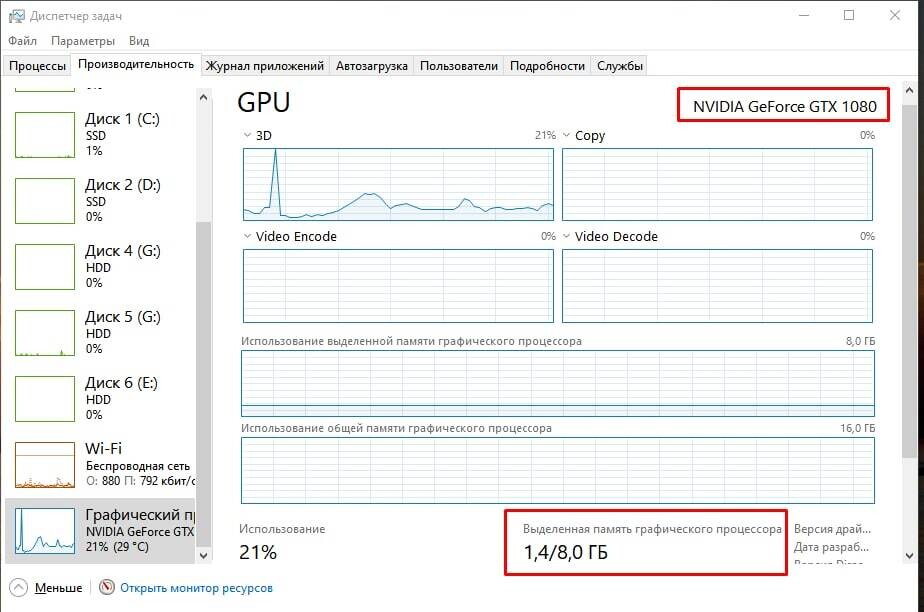
1. Еще раз убедитесь, что у вас Nvidia 10XX с хотя бы 4гб видеопамяти. Быстро проверить можно, зайдя в диспетчер задач (Ctrl+Shift+Esc), вкладку “производительность”, раздел “Графический процессор” и посмотрев на строку “Выделенная память графического процессора”.
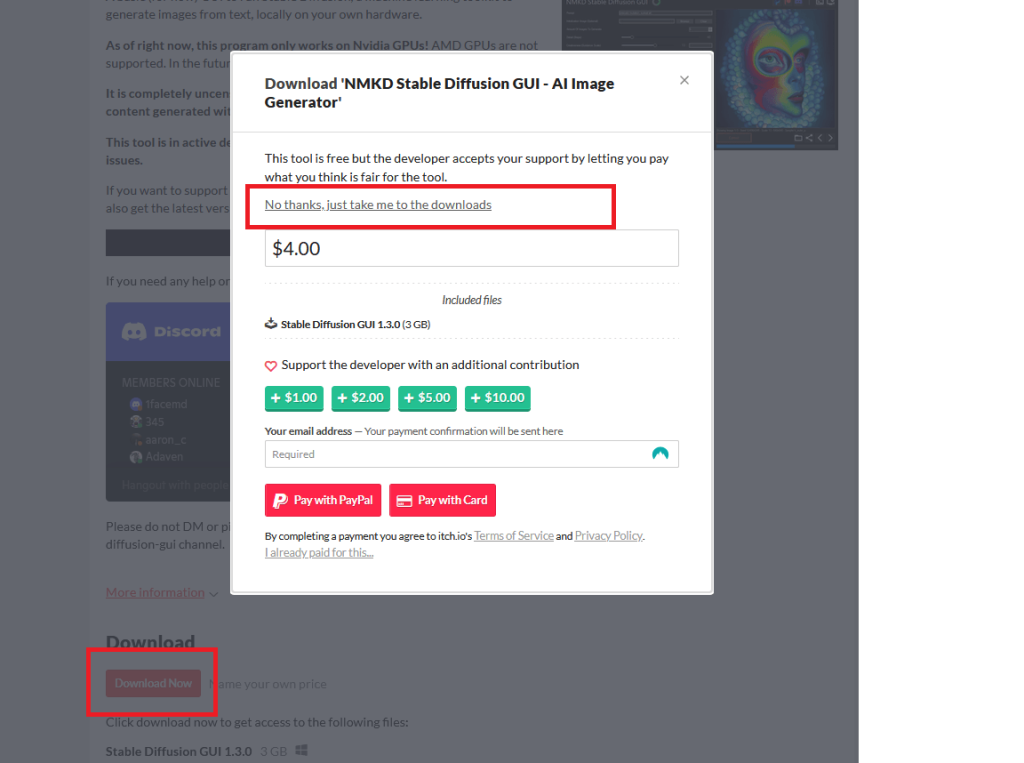
2. Скачиваете программу-установщик от NMKD
Нажимаете на красную кнопку “Download now” и решаете, поддержать ли вам разработчика деньгами или вы хотите скачать просто так. Никаких ограничений на вас не накладывается, если вы решите не платить. На следующей странице просто нажимаете “Download” и сохраняете архив там, где вам удобно. Весит 3 гигабайта.
3. Извлекаете содержимое архива куда вам удобно. Автор программы не рекомендует прятать ее очень глубоко из-за возможных ограничений на максимальную длину пути в файловой системе, но в данном случае это не так важно. Учтите, что программа + нейросети суммарно весят уже 11 гигабайт. У меня стоит на SSD, но не думаю, что это дает какую-либо ощутимую прибавку по скорости работы.
4. В распакованном архиве запускаете StableDiffusionGui.exe, соглашаетесь с возможными багами, и нажимаете на иконку установщика.
5. Последовательно нажимаете на “Download SD model”, “Clone Repo”, “Install Upscalers” и ждете, пока каждый из них скачается/установится. Прогресс можно наблюдать в левом нижнем углу приложения. Мне еще пришлось после этого делать Re-install, но вам может не пригодиться. Все поля должны быть отмечены галочками, если все прошло успешно.
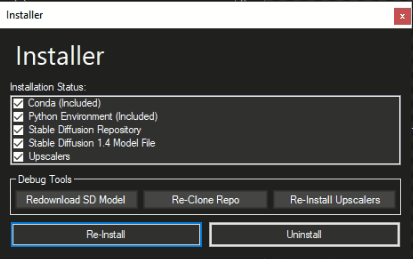
Так установщик выглядит после всех процедур.
6. Последний шаг – настраиваем место сохранения результатов и потребление видеопамяти. Заходим в настройки, отмечаем галочкой Low Memory Mode (если у вас меньше 8 гб видеопамяти), выбираем место сохранения результатов и то, надо ли создавать отдельную папку под каждый новый запрос к нейросетке. Я рекомендую создавать под-папки, так проще потом делиться результатами с остальными. Если вдруг ваш запрос к нейросети очень длинный и Windows не создаст папку с таким названием – картинки сохранятся в базовой указанной вами папке.
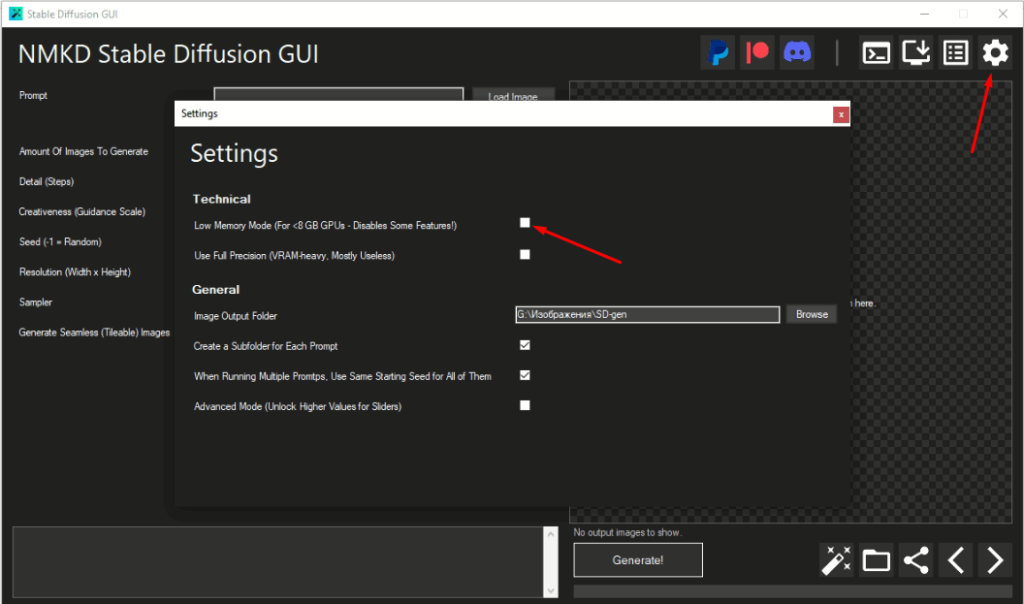
Поздравляю, вы справились!
3. Генерируем изображения по тексту
Самый базовый вариант:
Вбиваете в поле Promt свой запрос, нажимаете Generate, ждете.
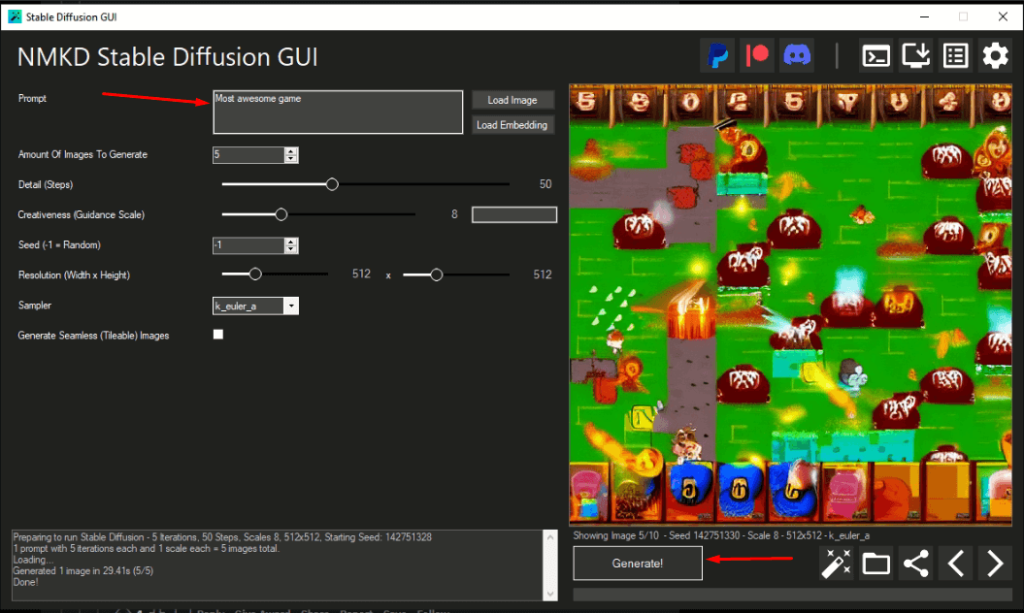
Какие настройки на что влияют (Подробнее – читайте в гайде):
- Сколько изображений нагенерировать. Больше изображений – дольше генерация, все просто.
- Steps – сколько шагов ИИ сделает в попытке выполнить ваш запрос. В теории, чем больше шагов, тем дольше обрабатывается запрос и качественнее результат, но на практике улучшение заметно не всегда. Для разных Sampler (о них ниже) оптимальное число шагов разное. По умолчанию рекомендуют 30-50. Если вас не устраивает какая-то часть изображения (например, глаза), лучше не увеличивать число шагов, а детализировать текстовый запрос к этой корявой части
- Creativeness (Guidance Scale) – насколько ИИ волен к интерпретации вашего запроса и должен ли он учитывать все его части. 2-6 – ИИ творит, что хочет, 7-11 – половину от вашего запроса возьмет, половину додумает, 12-15 – Постарается учесть большую часть вашего запроса, 16+ – Что написали, то и реализует. По умолчанию рекомендуется значение 8. Уверены в своем описании – 12.
- Seed – откуда ИИ будет стартовать свою отрисовку. Разные стартовые точки = разные итоговые результаты. Если вам не важна повторяемость результата – ставьте значение минус 1 . Если вы пытаетесь улучшить свой текстовый запрос – лучше зафиксируйте какое-то конкретное стартовое число и не меняйте его.
- Resolution – исходный разрешение получаемого изображения. Больше разрешение = больше видеопамяти нужно для генерации изображения. Нюансы – По умолчанию Stable Diffusion натренирован на изображениях 512*512, их он отрисовывает лучше всего. 256*256 – получается вырвиглазное нечто. Сделаете больше 512 – скорее всего он будет дублировать части изображения несколько раз в разных местах. Если вам нужно просто изображение большего разрешения, но с +- тем же числом деталей – лучше воспользоваться апскейлером (о них позднее). Не обязательно делать квадратные изображения, . Ходят слухи, что будет выпущена модель, обученная на 1024*1024 изображениях, но пока работаем с чем есть.
- Sampler. Я не знаю, как это работает “под капотом” (желающие объяснить – Welcome!), но с разными вариантами изображения генерируется немного по-разному. Наглядно это представлено на этом скрине:
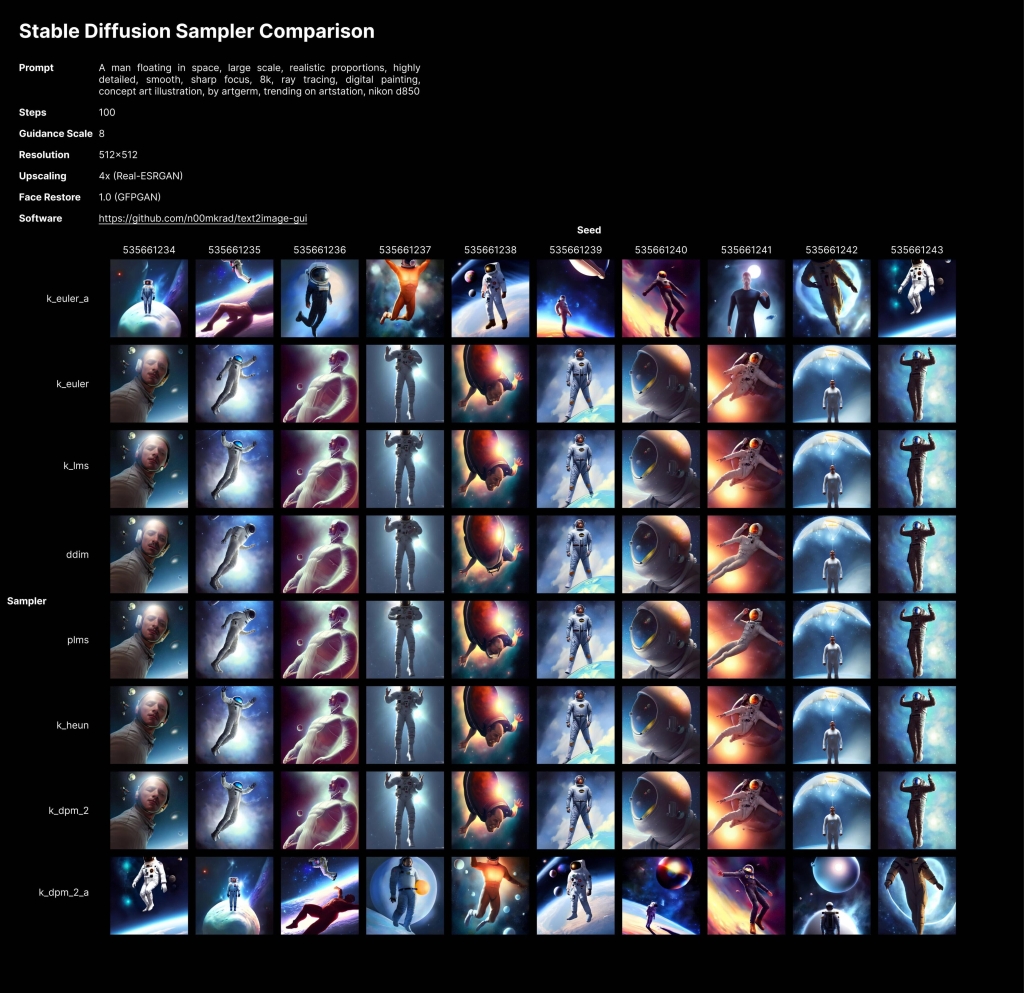
Как это описывает сообщество:
k_lms: The Old Reliable.Вариант по-умолчанию. Каждый шаг отрабатывается сравнительно быстро, но для хорошего результата нужно 50-80 шагов.
k_ddim: The Speed Demon. Хорош уже на 8 шагах, что позволяет быстро перебирать множество вариантов.
k_euler_a: The Chameleon. Быстр, что-то интересное выдает уже на 8-16 шагах, но с каждым шагом изображение может кардинально поменяться.
k_dpm_2_a: The Starving Artist . Медленный на каждом шаге, нужно больше шагов для генерации приличного качества (50-80), но результат дает чуть более детализированный, по сравнению с тем же k_euler_a.
Для начала я обычно генерю с k_euler_a и 20 шагами. Если корявые глаза-руки, а в остальном норм – ставлю k_dpm_2_a и 75 шагов.
3.5 Особенности текстовых запросов
Если вы уже знакомы с Midjourney и тем, как хорошо генерировать запросы для него – переносите свои навыки на Stable Diffusion, только помните, что здесь нет команд вроде –wallpaper, –beta и нет опции разделять сущности через :: (можно через веса, об этом позже)
Уже существуют сайты, на которых вы можете посмотреть, что выдаст SD при том или ином запросе (https://lexica.art/). Посмотрите на то, как люди формируют запросы по сходной тематике, вдохновитесь и используйте их как основу для своих собственных изображений. Удаляйте части запроса, добавляйте новые и смотрите к какому результату это приводит. Посмотрите на самые популярные работы в сообществе и как к ним был составлен текст.
Можете попробовать использовать генераторы описаний, в которых уже есть какие-то известные элементы описаний, на которые реагирует ИИ. Например, вот этот
Сейчас считается, что чем конкретнее и многословнее будет ваш запрос – тем лучше. Описывайте одно и то же разными словами. Хотите высокой детализации? Пишите “Masterpice, high quality, ultra-detailed, 4k” и что-нибудь еще. Или указывайте автора, рисующего в гипер-реалистичной манере через запрос “by %Фамилия-Имя автора%, из тех ,что есть в датасете LAION. Или даже несколько похожих авторов сразу.Или непохожих, для большей художественности. Что мешает смешать Моне и Ван Гога? Синьяка и Хокусая?
Учтите, что больше 75 слов за раз SD не воспринимает.
Важен также и порядок слов в запросе – чем ближе к началу, тем, по-умолчанию, больший вес этому слову придаст нейросеть. Так что ставьте на первые места те элементы, которые точно должны быть в изображении.
Хорошо сразу вряд-ли получится, не волнуйтесь. Для того, что бы получилось что-то, что уже хочется показать, обычно надо перебрать много разных модификаций одного и того же запроса, да еще и с разными настройками. Именно поэтому и не рекомендую начинать с k_lms и 50 шагами – когда генерируешь 100 разных запросов, имеет значение, сколько отрабатывает каждый из них.
Есть возможность вручную указывать веса для каждого элемента (насколько нейросеть должна учесть каждый). После целой фразы ставите “:xx”, где xx – вес этого элемента при генерации.В сумме веса всех элементов должны давать 100. Пример запроса для генерации наполовину мини-дракона, наполовину – хорька под картинкой
4.Модификация готового изображения
Замечательная опция, о которой многие забывают – можно дать изображение, которое выступит основой для генерации.
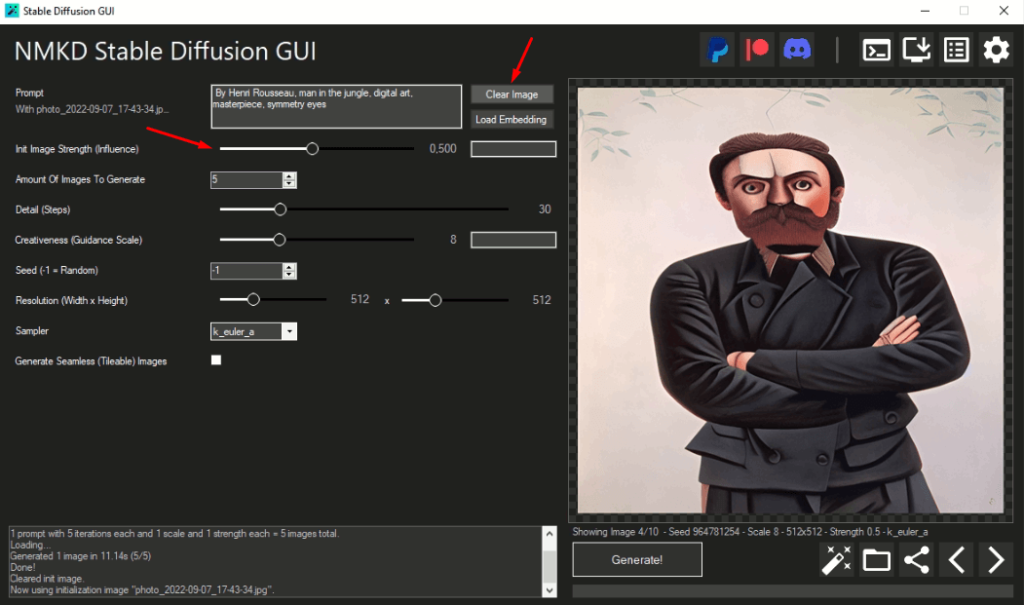
У вас появится возможность настроить вес вашего исходного изображения и текстового описания, которое послужит основной для модификации. В данной программе чем ближе выставите слайдер Strength к 0, тем больше изображение будет похоже на текстовое описание. Чем ближе к 1 – тем больше на исходное изображение.
Я обычно выставляю около 0.4-0.6, получается сохранить детали и запроса и исходника. Когда ставлю больше 0.6 с фотографиями людей начинается творится хтонический ужас. Меньше – слишком далеко от оригинала.
5. А что дальше?
Начните уже что-то генерировать, получайте от этого удовольствие и дарите его другим. Следите за тем, какие новые возможности и удачные примеры появляются в сообществе на гитхабе/реддите и других площадках. Попробуйте освоить генерацию по образцу, когда вы используете набор изображений в качестве маленькой обучающей выборки, и потом генерируете изображения в этом новом “стиле”.
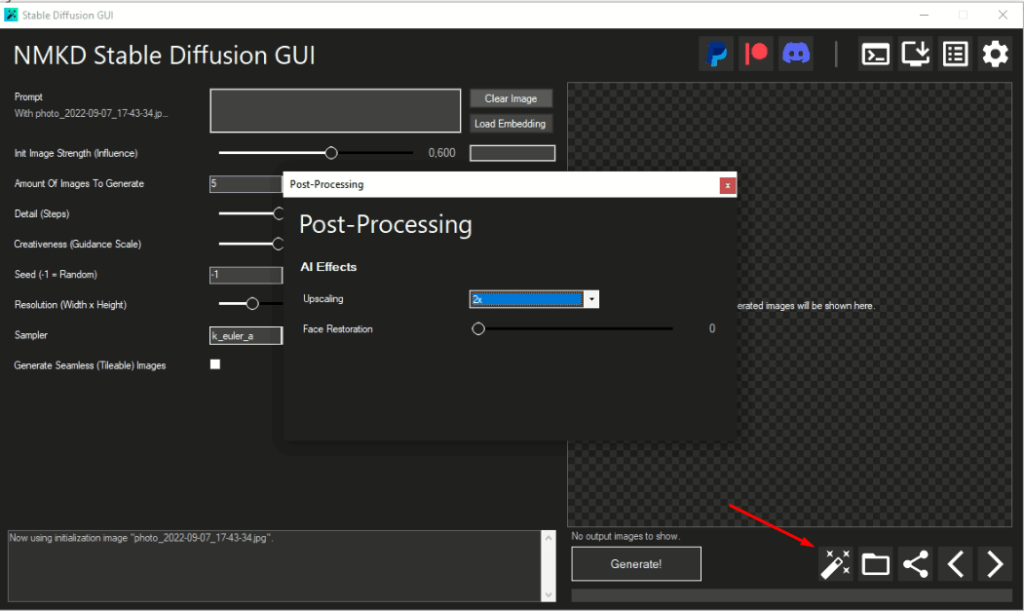
Попробуйте использовать различные улучшатели изображений. В описываемом мной варианте есть два разных, один – для повышения разрешения, второй – для повышения качества лиц (RealESRGAN и GFPGAN)


1 Comment
И где анлок?